Abstract
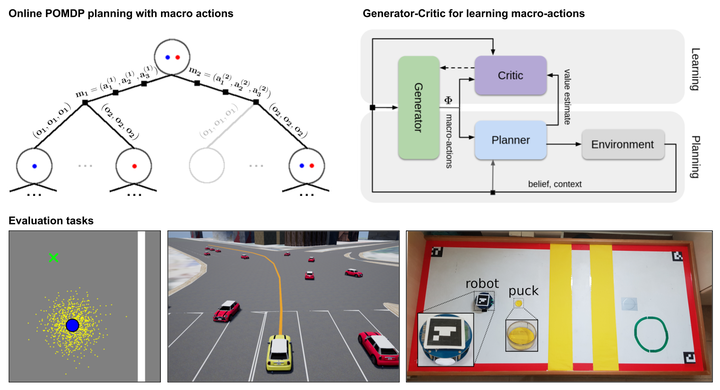
When robots operate in the real world, they need to handle uncertainties in sensing, acting, and the environment dynamics. Many tasks also require reasoning about long-term consequences of robot decisions. The partially observable Markov decision process (POMDP) offers a principled approach for planning under uncertainty. However, its computational complexity grows exponentially with the planning horizon. We propose to use temporally-extended macro-actions to cut down the effective planning horizon and thus the exponential factor of the complexity. We propose Macro-Action Generator-Critic (MAGIC), an algorithm that learns a macro-action generator using feedback from a planner, and in turn uses the learned macro-actions to condition long-horizon planning. Importantly, the generator is learned to directly maximize the down-stream planning performance. We evaluate MAGIC on several long-term planning tasks, showing that it significantly outperforms planning using primitive actions and hand-crafted macro-actions in both simulation and on a real robot.